Si estás buscando ampliar tus conocimientos de posicionamiento web, es muy probable te preguntes para qué sirve el archivo robots.txt y si realmente lo necesitas. Y en el blog de SEO de nuestra agencia de posicionamiento web te lo vamos a explicar con detalle.
Como sabes Google visita nuestras webs periódicamente y rastrea los diferentes contenidos que tenemos en ella a través de sus “robots” (de ahí el nombre del archivo robots.txt), también conocidos como crawlers o arañas.
Pero, además del famoso Googlebot de Google, existen otras arañas populares que también aceden a tu página, como Yahoo_Slurp de Yahoo o Msnbot de Bing. Estos crawlers rastrean nuestra web y van descubriendo los nuevos contenidos que vamos añadiendo, los valoran y por último los indexan en los resultados de búsqueda (SERPs) según dicha valoración.
Entonces, ¿qué pinta este archivo en todo esto? Sigue leyendo para descubrirlo.

Para empezar ¿qué es el archivo robots.txt?
El archivo robots.txt es un archivo situado en la raíz de tu sitio web que da instrucciones a los robots de los motores de búsqueda.
Con estas instrucciones realizadas a través de comandos en el fichero, indicas a los crawlers cómo deben comportarse dentro de tu web y consecuentemente cómo realizar el rastreo y posterior indexación de tus contenidos de la manera que más te interese.
Para qué sirve el archivo robots.txt
Vale, una vez sabemos qué es el archivo robots.txt, resulta básico conocer sus principales usos y cómo podemos sacarle partido dentro de nuestra web.
Estas son algunas de las formas más comunes en las que se emplea:
- Para restringir el acceso a determinadas partes de tu web a las arañas de los motores de búsqueda usando determinados comandos aplicados a este archivo.
- Con una buena configuración del robots.txt podrás optimizar el crawl budget o presupuesto de rastreo, es decir, el tiempo que los robots de los motores de búsqueda destinan a rastrear todos los contenidos de tu web. Si lo configuramos de tal manera que el bot no tenga que rastrear contenido que tenga poca importancia dentro de tu sitio web o contenido que sea muy similar (contenido duplicado o paginaciones), estaremos optimizando gran parte de dicho presupuesto de rastreo.
- Utilizando una serie de comandos que más abajo te detallamos, en este archivo además de restringir de manera sencilla la accesibilidad del bot a directorios, subdirectorios, archivos y URLs específicas de tu web, podrás especificar el sitemap de tu web.
Pero como venimos comentando, todo esto son indicaciones para los robots y no garantizan que una página no se muestre en los resultados de búsqueda definitivamente, porque también entraran en juego los enlaces entrantes que estén recibiendo esas URLs que hemos decidido restringir.
Por lo que si se quiere desindexar concretamente una página para que deje de mostrarse en los resultados de búsqueda, la mejor opción siempre es implementar la metaetiqueta robots “noindex”, sin que esté restringido el acceso mediante el archivo de robots.txt a dicha página, ya que será necesario para el robot poder rastrearla y detectar dicha metaetiqueta de indexación.
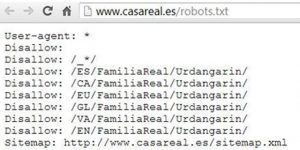
En la siguiente imagen podemos ver un ejemplo de aplicación, que fue muy viral en internet en su día, de cómo la Casa Real utilizaba el archivo robots.txt para restringir el acceso a los bots a los subdirectorios (en todos los idiomas) relacionados con Iñaki Urdangarin (todos sabemos porqué).
¿Realmente lo necesito?
El archivo robots.txt no es obligatorio, simplemente lo crearemos si queremos restringir algunas partes de la web de cara a los robots de los motores de búsqueda.
En concreto, será interesante crear un archivo robots.txt si quieres:
- Ocultar partes de tu web a los motores de búsqueda.
- Restringir acceso a contenido duplicado.
- Restringir acceso a archivos de código.
- Indicar el Sitemap de nuestra web a los bots.
- Restringir ciertos directorios o subdirectorios de tu web.
Si deseas conocer más sobre cómo mejorar la indexación y navegación de tu web, te recomendamos que visites a nuestra Agencia SEO Barcelona, donde asesoramos a empresas para sacar el máximo partido a su estrategia online.
Comandos del robots.txt
Bien, ahora que sabes qué y para qué sirve el archivo robots.txt, y una vez que has podido determinar si realmente lo necesitas configurar para tu proyecto, te vamos a indicar los comandos principales que puedes implementar en él.
Estos serían:
- User-agent: Indica sobre que robot se aplicarán las reglas que escribiremos a continuación.
Si ponemos User-agent: *, estaremos indicando que las reglas serán para todos los bots.
Si ponemos, por ejemplo, User-agent: Googlebot, solo este bot cumplirá las reglas descritas.
- Disallow: Aquí podremos restringir el acceso a un directorio, subdirectorio o página en concreto.
Por ejemplo, Disallow: /wp-admin/
- Allow: Todo lo contrario que disallow, sirve para dar acceso a nuestra web. Sirve para decirle a los robots que una parte de las páginas que habíamos puesto bajo la regla de Disallow, sí queremos que las rastreen.
- Sitemap: Con este comando les indicaremos la ruta de nuestro mapa del sitio
Ejemplo: Robots.txt de BigSEO Agency
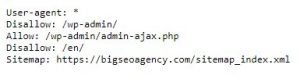
En User-agent, con el * estamos indicando que llamamos a todos los bots.
En la segunda línea con el Disallow, estamos indicando que no queremos que accedan a /wp-admin/. Y justo después, le especificamos que dentro de esa parte, todo lo que sea admin-ajax.php sí lo rastreen.
En la cuarta línea volvemos con un Disallow, indicando a los robots que no rastreen nada bajo el subdirectorio /en/.
Y por último, le indicamos la ruta de nuestro Sitemap XML.
Si tienes más preguntas o necesitas ayuda para configurar el archivo robots.txt de tu sitio, no dudes en contactar con nosotros. En nuestra Agencia SEO estamos para ayudarte a mejorar cada aspecto del posicionamiento web.
Y si deseas profundizar en las técnicas y estrategias avanzadas de SEO, nuestro Máster en SEO te brindará todas las herramientas y conocimientos necesarios para llevar tu proyecto al siguiente nivel.
¡Optimiza tu web y haz que los motores de búsqueda trabajen a tu favor!




Hola
¿Cual es la ventaja de robots txt de pago?
Hola equipo,
Tengo una duda de robots.txt. por si pueden resolverla. Nadie lo sabe…
Si tengo urls con «#» provocadas por tabla de contenidos del indice de mi blog, para evitar canibalizaciones ¿tendría que hacer un disallow de todo lo que lleve #? La search console me indica que por la misma kw llegan por varias urls pero son variantes de la misma con los # de los jump links…
En este caso mi duda es como sería:
La url en cuestión que genera los #: http://www.medicinafernadez.com/dolor-de muelas/#soluciones medicas
Obejtivo: hacer disallow solamente a lo que lleva # salvo que sea bueno para el posicionamiento.
Tengo dos opciones:
1. Disallow: /#* ( ¿así aplicaría a todos los post con #?).
2. Disallow:*#* ( me parece que haría disallow a todo lo que lleva delante y no sería correcto)
3. Disallow: /dolor-de muelas/#soluciones médicas ( entiendo que está mal por que me hace disallow también de la url /dolor-de muelas/ y eso no lo quiero)
4. Allow: /dolor-de muelas/$ ( la veo bien pero tendría que hacerlo con todos los post del blog y desconozco si le hace trabajar más a google si lo hago con 100 urls…)
Muchas gracias , espero que puedan ayudarme, en internet no hay nada de nada al respecto de los table of content o indices de los blogs cuando generan los # de los jump links.
Buenas.
Tengo una página web y uso yoast seo,pero no tengo instalado el archivo robots.txt. solo tengo cargado el sitemap en google search console.
¿Es necesario que cree este archivo robots.txt o solo con yoast seo sería suficiente?
Gracias